Pour ceux d'entre vous qui ont une BMW R1250RT (sans écran TFT), j'ai compilé une petite liste qui pourrait peut-être vous être utile.
Friday 17 January 2025
R1250RT
By glazou on Friday 17 January 2025, 16:21
Friday 17 January 2025
By glazou on Friday 17 January 2025, 16:21
Pour ceux d'entre vous qui ont une BMW R1250RT (sans écran TFT), j'ai compilé une petite liste qui pourrait peut-être vous être utile.
Tuesday 24 May 2022
By glazou on Tuesday 24 May 2022, 11:18
Ce blog fête aujourd'hui même son vingtième anniversaire. Je l'avais commencé pendant que j'étais chez Netscape comme une expérimentation pour écrire ce qui me passait par la tête. Jamais je n'aurais pensé que cela dure deux décennies...
Wednesday 16 June 2021
By glazou on Wednesday 16 June 2021, 14:14
<tldr> Joël Courtois a annoncé récemment aux élèves de l'Epita son départ après plus de deux décennies à la tête de l'établissement et le groupe IONIS est à la recherche d'un nouveau Directeur Général pour l'EPITA </tldr>
<disclaimer> les anciens Epita croisés soit dans ma carrière soit dans ma vie privée sont tous, je dis bien tous, des excellents informaticiens de haut niveau. Voir cependant plus loin dans le texte quelques "modulos". </disclaimer>
L'Epita, je la croise depuis si longtemps... Quasiment tous les jours quand, étudiant dans le 13ème arrondissement de Paris, je passais devant ses bâtiments. Ou quand peu de temps plus tard, mon premier employeur y faisait envoyer la DST, les tentatives de piratage venant d'une salle bien précise de l'Epita et des élèves d'un certain enseignant devenant trop nombreuses (c'était bien avant l'époque IONIS, il y a prescription ; au sens réel et figuré). Puis quand j'ai rencontré des Epita comme clients. Puis comme collègues.
Et un jour j'ai vu mon fils cadet pleurer de joie, vraiment, à chaudes larmes, en apprenant qu'il était pris à l'Epita, dans la section dite "anglophone". J'étais heureux pour lui, et même fier. Je le prévenais que cela serait dur mais j'étais confiant : un gamin qui soudait lui-même ses circuits intégrés sur le cuivre à 9 ans et codait la majeure partie (back et front) d'un site ayant gagné un prix européen pouvait y arriver.
J'ai commencé à avoir des premiers doutes lors de mon passage à l'Epita pour une réunion "Parents / Direction" en comparant tout simplement l'attitude générale et les mots d'accueil du Directeur de l'École d'Ingénieurs Nationale de mon second fils, et ceux de Joël Courtois, le ci-devant Directeur de l'Epita depuis, tenez-vous bien, Avril 1997 et qui a annoncé récemment aux élèves son départ...
Au bout de deux minutes à peine et dans des poses physiques de lieutenant-colonel accueillant sa bleusaille sur la place d'armes du régiment, le "king" Courtois expliquait aux parents consternés que 25% de la promo de première année échouerait. Son collègue gérant l'école de mon fils aîné nous offrait, quelques jours auparavant, son plus beau sourire pour nous expliquer, ré-expliquer et ré-expliquer encore avec bonhommie et douceur que sa mission première est d'amener tous les élèves à l'épanouissement, les amener tous à l'obtention du diplôme et les soutenir avec bienveillance.
Tout le reste du discours de Courtois respirait un « ils ont signé pour en chier » et du « on va leur en faire baver » qui encore aujourd'hui me reste clairement en travers de la gorge, et je suis passé moi-même par une École Militaire... La promesse d'un stage commando de 5 ans du côté Epita, des années d'études joyeuses de l'autre. Avec le même taux d'accès au CDI des deux côtés.
J'ai discuté quelques minutes avec Joël Courtois après cette séance éprouvante. Un seul mot m'est venu à l'esprit : condescendance. J'étais un parent de futur élève à qui l'Epita faisait l'aumône d'accueillir son rejeton. J'en suis sorti outré.
J'ai ensuite basculé dans la consternation dès les premières semaines suivant la rentrée avec les évaluations : très rapidement, l'Epita procède à l'évaluation de ses nouveaux étudiants et s'il s'agit d'une forme de bizutage, il est particulièrement brutal. Les évaluations sont conduites via des QCM à points négatifs, système qui bien entendu n'aura pas été expliqué ni appliqué "en blanc" aux gamins et qu'ils n'ont jamais utilisé de leur vie scolaire. Surtout qu'on a bien précisé aux parents que ces évaluations sont déterminantes et qu'un gamin qui les plante a en fait peu de chances de s'en remettre. Pour casser un gamin dès son arrivée, c'est parfait ; pour lui dire « bienvenue dans vos plus belles années, celles de vos études supérieures », vous me permettrez d'avoir un très gros doute. Les premières notes sont évidemment parfois désastreuses, j'ai vu moi-même des jeunes Epita qui en rêvaient, après une Terminale brillante, envisager de quitter l'École au bout de seulement trois semaines de présence, un comble.
Ce système de QCM à points négatifs perdurera toutes les études. Il est donc parfaitement possible de se taper un zéro strictement pointé à l'Epita pour des résultats qui offriraient absolument partout ailleurs un diplôme d'Ingénieur, non usurpé.
Car l'Epita c'est aussi une École d'Ingénieurs. Elle est contrainte par la CTI, la Commission des Titres d'Ingénieur. Elle a deux années préparatoires aux trois années d'études proprement dites. Elle les appelle Info Sup et Info Spé, deux noms très bien choisis. Mais même en Maths Sup et Maths Spé, que j'ai fréquentées personnellement ou via mon fils aîné, mon neveu, les enfants de mes amis, on ne bouzille pas les gamins comme ça. Certes, certes, la boutade habituelle du prof principal le premier jour « il vous reste une minute pour changer d'avis » est courante mais elle est toujours prononcé avec un grand sourire. En CPGE, on choye ses élèves ; on les fait bosser très dur mais on y fait également aussi très attention. On les accompagne.
Puis les cours arrivèrent. Alors que l'Epita coûte annuellement la peau des couilles pour une École d'Ingénieurs et que les parents attendent que pour ce prix-là l'école dispose d'enseignants faisant - quelle horreur! - des cours, des vrais cours quoi, la plupart sont des vidéos pompeusements appelées MiMos. Là où cela ne va plus du tout, c'est que toutes ces vidéos - loin s'en faut - ne sont pas produites par l'Epita... J'ai personnellement visionné quelques-unes de ces vidéos de cours, produites par je crois l'Université de Lille. La plupart étaient de piètre qualité tant pédagogique que scientifique. Pire, le programme du MiMo était parfois incomplètement adapté au programme de l'Epita. (nota bene : j'ai été prof d'informatique en Maths Spé et je suis un matheux.)
Pendant ce temps-là, Courtois a eu le culot de se répandre dans la presse en disant que « le coût de la scolarité est relativement indolore ». Quelle indécence, quel mépris pour certaines familles qui se saignent et ne voient de l'Epita quasiment qu'un seul message par an : merci de payer la prochaîne année d'études de votre gosse avant telle date et, au fait, le coût a pris 10% encore une fois évidemment sans qu'on vous prévienne ; et bien entendu vous n'avez pas le choix puisque si votre gamin ne continue pas, il peut direct se ré-inscrire à Parcours-Sup, il n'a aucune équivalence.
Évidement, la crise Covid n'a rien arrangé. Aucune mansuétude pour le contexte difficile, mauvaise qualité des supports des cours, aucun support non-vidéo, jmenfoutisme total de certains enseignants, locaux décrépis, on coche toutes les cases d'un lieu qui sent tout de même beaucoup plus fort l'entreprise commerciale pure que le campus heureux. Quand j'ai suggéré à la Scolarité qu'en cette période difficile de cours strictement en distanciel, il serait peut-être une bonne idée de filer aux élèves des supports de cours "papier" pour les aider à passer le cap, la réaction fut « on n'y avait pas pensé ». Mais nom de Zeus, vous pensiez à quoi alors ? Quant à savoir s'ils l'ont fait, d'après vous ?
Il faut dire que l'Epita, c'est aussi un site et des bâtiments au Kremlin-Bicêtre qui, euh, comment dire, ne font pas franchement rêver, voilà. Même pas de cantine ou tout simplement de lieu pour s'asseoir et manger leur déjeuner pour les étudiants. Des bâtis extérieurs de fenêtre tellement défoncés que des moineaux ont fait leur nid à l'intérieur ! Des murs qui font pitiè. C'est moche, ça fait pas envie. En tous cas, pas à moi.
Le soutien venant de la Scolarité est indigent et à l'image de Joël Courtois : brutal. En gros, un élève qui ne réussit pas immédiatement à s'adapter au système de l'Epita (pourtant très inhabituel) est presqu'un raté qui n'a rien à foutre là.
À l'Epitech qui partage les locaux et surtout la mentalité avec l'Epita, et où le Kwisatz Haderach a aussi sévi, même combat. Ma machoire en est tombée quand on m'a raconté la note de -42 (oui, vous avez bien lu, MOINS QUARANTE-DEUX) qu'on peut obtenir pour une erreur minime. Irratrapable, donc. Cela doit les faire marrer de donner une note négative tuante avec le chiffre 42 dedans, je suppose. Permettez-moi de ne pas rire ni même sourire, je trouve cela tout simplement lamentable et de mon point de vue, un tel management mériterait uniquement un licenciement immédiat pour harcèlement moral envers les élèves.
Quand on bascule dans les trois années d'Ingénierie à l'Epita, on n'est pas tiré d'affaire pour autant. La fameuse Piscine arrive, un véritable stage de Légion Étrangère en Guyane qui n'existe nulle part ailleurs dans le monde et durant lequel les élèves se voient donner un projet irréalisable dans le temps imparti sans y être investi, au sens propre du terme, 24h sur 24. Quelle ne fut pas ma surprise quand la Direction de l'École nous a expliqué qu'on ne laissait plus les élèves passer la nuit au travail ou dormir sous les tables dans les salles de cours pendant la Piscine mais qu'on les renvoyait chez eux à (je crois) 1h du matin. Quelle ne fut pas ma surprise également quand des élèves d'Ingé1 m'ont confirmé que cela perdurait parce qu'il n'y pas le choix, ça continue juste à domicile. Mais nom de Zeus, s'il y a des coups de bourre en Informatique, ce n'est pas ça l'Informatique. L'Informatique, c'est un métier de bonheur dans lequel on fait marcher son cerveau à pleins tubes, pour lequel on se lève avec plaisir le matin et on saute sur son clavier avec délectation. Un cours d'Informatique, un projet d'Informatique, ce n'est pas un parcours du combattant, c'est apprendre à apprendre, c'est acquérir la capacité à voir la beauté d'un code ou d'une technologie et ouvrir le champ des possibles, devenir capable d'évaluer une complexité et écrire un plan d'attaque. L'enseignement de l'Informatique, ça doit être un épanouissement, pas un épuisement débile et surtout inutile.
Est-ce que ma formation Informatique personnelle souffre de n'avoir pas eu de Piscine ? Évidemment que non. Est-ce qu'un gamin passé par l'IUT ou la fac est moins bien formé aux coups de bourre ? Mais bien sûr que non. Est-ce que scolairement, cela amène quelque chose à part de la fatigue, du stress, de la brutalité ? Meuh non.
De ce point de vue, les « méthodes éducatives innovantes » de l'Epita et l'Epitech me semblent surtout des moyens de filtrage et de réduction des coûts professoraux.
J'ai également entendu plusieurs fois des rumeurs alarmantes de sexisme totalement déplacé, et qui méritent donc d'être citées ici si d'aventure elles étaient avérées. Elles m'ont été rapportées par plusieurs anciens élèves, tant anciens que récents. Cela reste à prendre avec des pincettes, mais tout de même.
En fait, l'Epita vit dans un monde vieux de plus de 20 ans imposé par un Directeur qui n'a pas su évoluer avec le temps. On n'est plus en 1998, ni même en 1984, date de fondation de l'Epita. Mais même il y a 20 ans, cette brutalité des méthodes était déjà inutile. En 2021, elle est anachronique, déplacée et surtout contre-productive.
Il y a un effet de bord à cette brutalité scolaire. J'ai vu de mes yeux certains Epita, anciens ou récents, incapables de ne pas reproduire professionnellement les schémas qui leur ont été inoculés à l'Ecole, je les ai vus appliquer à l'envi les méthodes militaires de leur École dans la vraie vie et exiger de leurs subordonnés ou collègues un niveau d'engagement tout simplement indécent et se comporter de façon scandaleuse, à la limite du harcèlement moral. J'ai entendu de telles personnes dire, je cite, « ouais, pas grave, moi aussi j'ai déjà du dormir sous le bureau pendant mes études, on n'en crève pas ». Je n'arrive pas à ne pas avoir honte en face de tels comportements.
Alors oui, je l'ai dit et je le redis, les Epita sont des excellents Ingénieurs en Info. Les Epitechs sont des excellents Informaticiens (j'ai un beau contre-exemple en tête mais un seul, donc ça ne compte pas). Mais très franchement, je me demande s'ils ne sont pas tout simplement intrinsèquement bons et si ils ne seraient pas tout aussi bons en autodidactes. L'Epita leur offre, contre moultes espèces sonnantes et trébuchantes, le diplôme, le bout de papier qui va bien. Mais ils sont techniquement balaises, demandeurs, passionnés, ils auraient le même niveau partout ailleurs et même en dehors de tout système scolaire.
Je suis donc persuadé que l'Epita gagnerait immensément à :
Mon fils quitte donc l'Epita, dégouté par son système. Sur trois copains du même lycée qui rêvaient d'y entrer et sont allés jusqu'à prendre un appart en colloc ensemble pour cela, deux ont abandonné, dépités. Le premier est parti au Canada, accepté à l'Université McGill, excusez du peu, et y mène une très belle scolarité. Le second va rester en France, toujours dans la babasse, mais en un lieu où l'humain compte un peu plus. Le départ de Courtois est une opportunité à saisir, il faut un vrai virage sur l'aile, une rupture, pour que ce genre d'échec créé par le système ne se reproduise plus. Et je fais parfaitement confiance à la nouvelle Direction pour le réaliser.
J'ai conscience que les mots qui précèdent sont ceux d'un déçu. Car oui, je suis très profondément déçu par ce que j'ai pu voir, de mes propres yeux, de l'Epita, une école qui vit sur sa réputation et a brisé connement et surtout inutilement mon gamin. Il sera donc aisé de dire de moi « c'est un aigri mal informé », « il mène sa croisade ». Je l'ai déjà entendu dire, de mes propres oreilles, d'un autre parent d'élève dans le même cas, par cette Direction sortante. Chiche.
Tuesday 3 November 2020
By glazou on Tuesday 3 November 2020, 09:57 - General
Mon ami, mon poteau, mon marin insubmersible.
Je me souviens de tes éclats de rire, de ton enthousiasme, de ta chaleur. De ton amitié.
Je me souviens de ton coup de fil « j'envisage de quitter la Marine et j'ai besoin de ton aide et de tes conseils ».
Je me souviens à quel point tu as rougi quand tu m'as annoncé, dans ce bar à vin à côté du Marché Saint-Honoré, que ta femme attendait un enfant.
Je me souviens de tes appels récurrents « j'ai quelqu'un à te présenter, je pense que vous pourriez bosser ensemble » ou « j'ai eu une idée de projet, j'ai besoin de ton opinion ».
Je me souviens de ton engagement sans faille, et de toujours, en faveur du Logiciel Libre.
Je me souviens de mon plaisir intense à te croiser, partout, tout le temps. Pendant près de vingt ans.
Je regarde ton dernier tweet, une réponse à une des mes bêtises sans importance. Tu vas immensément me manquer, nous manquer. Le Logiciel Libre est un peu plus vivant en France grace à toi, Laurent Séguin. Et je pleure l'ami fidèle.
Thursday 30 April 2020
By glazou on Thursday 30 April 2020, 15:21 - General
I just understood one interesting thing: the notion of "observable universe" is not limited to light (in the general sense). Gravity is also moving at the speed of light so whatever the masses laying outside of our observable universe, they do not affect us, will not affect us, will never affect us whatever they do.
Even weirder: the notion of "observable universe" is centered on the observer. So imagine a galaxy at the limits of our observable universe, but inside. Imagine it's affected by something lying just outside of OUR observable universe because that "something" is inside ITS observable universe. We'll never see how it is affected either. Because the total time of gravity application from source to galaxy and then of light travel between the galaxy and us is greater than the age of the universe.
In short, it's impossible, for all our observable universe, to observe any effect on anything inside it from outside it, even if that "anything" is closer to us. This drives me crazy, it's another event horizon.
Sunday 1 March 2020
By glazou on Sunday 1 March 2020, 18:57 - General
Vingt ans que je rêvais de conduire un BMW RT. C'est chose faite, je suis depuis le 25 janvier l'heureux possesseur d'une R1250RT toutes options. Je redécouvre (je pourrais même dire que j découvre) le plaisir de la moto, j'ai rajeuni de dix ans. Et pour ceux qui se poseraient la question, oui mon dos la tolère très bien : le confort est tel que je ne sens que peu la route ; mon kiné m'a dit que les micro-mouvements du dos faits pour équilibrer et diriger correspondent à un petit gainage. Un ex-collègue qui se reconnaîtra, qui souffre également du dos et roule en 1200GS, me l'avait dit mais j'avais du mal à y croire. Et bien je confirme :-)

On va faire trois petites listes... Ce qui est fabuleux sur cette moto :
Ce qui l'est moins :
Je me suis donc attelé à chercher des accessoires sympas :
Voilà. En hopant que ça helpe. Si vous roulez en 1200RT ou 1250RT et que vous avez des tuyaux sympas, je suis preneur.
Monday 2 December 2019
By glazou on Monday 2 December 2019, 14:54 - Franchouillardises
Allégorie :
Monday 9 September 2019
By glazou on Monday 9 September 2019, 14:46 - Glazblog
Juste un petit truc pour dire que je suis fier de mes fils et que je les aime :-)

Friday 5 July 2019
By glazou on Friday 5 July 2019, 14:56 - Franchouillardises
Décidément, on n'a pas de bol avec nos Secrétaires d'État au Numérique...
| Tweet | Mon commentaire |
|---|---|
 |
Eeeeh non Cédric. L'internet est né bien avant. Le Web est né il y a 30 ans et cela n'a rien à voir. De plus toute la phrase est complètement fausse concernant le Web. Extrait du document d'origine de Tom Berners-Lee : « This proposal concerns the management of general information about accelerators and experiments at CERN » |
 |
Tout système sera toujours abusé. Le Minitel a donné du Minitel rose. La Politique a donné les politiciens verreux. Rien de nouveau. |
 |
Vous avez entendu parler de la Loi Pleven ? |
 |
Vous avez entendu parler du Principe de Qualification ? |
 |
*facepalm* |
 |
« Notre humilité est notre certitude d'avoir raison »... |
 |
La Liberté d'expression est déjà là et dispose déjà de tous les arsenaux juridiques nécessaires à son application. La seule différence, que votre loi ne changera pas, c'est qu'on ne peut rien contre un haîneux basé loin du territoire national. Vous avez réussi à faire arrêter et extrader Boris Le Lay ? |
 |
Libérale donc régulatrice. J'aurais préféré lire "les outils digitaux au service de la connaissance", j'aurais plus ri :-) |
 |
*facepalm again* |
 |
Cette phrase a presqu'exactement déjà été prononcée par un homme politique devant moi au Sénat en 1997. Il n'y a aucun non-droit sur Internet. Demandez donc à Me Bensoussan. |
Sunday 30 June 2019
By glazou on Sunday 30 June 2019, 15:26 - General
Nota bene important : cet article n'est PAS un article sponsorisé ou vendu, ni de la pub. J'ai acheté une capsule réutilisable I CAFILAS pour mon propre usage, et cet article ne reflète que mon opinion faisant suite à cet achat.
Possesseur depuis très, très longtemps de machine Nespresso, j'ai voulu tester des capsules réutilisables. Je me suis d'abord tourné vers des capsules en plastique de maïs fermé par une membrane autocollante. J'ai assez rapidement déchanté à cause du pré-perçage de la capsule qui fout du café partout et de la complexité de la fermeture de la capsule autocollante.
Puis en cherchant une housse de transport pour une machine Nespresso, je suis tombé par le plus grand hasard sur des capsules réutilisables, en métal, de la marque I CAFILAS. Trouvant le prix sur Amazon un peu abusif, J'en ai commandé une sur AliExpress fournie avec un petit tamper, une petite brosse et une mesurette. Elle est arrivée en dix jours sans souci.


L'emballage est propre, les contenus sont bien protégés par du papier-bulle et un petit sachet plastique. Voici ce que ça donne une fois déballé :


La capsule elle-même est de très bonne facture et les joints sont propres. Le filtre est très bien réalisé. Le tamper est lourd, bien dessiné, et est vraiment assez chouette. Ayant du café moulu de bonne qualité, j'ai immédiatement essayé.
Côté remplissage c'est assez propre mais un mini-entonnoir au bon diamètre serait mille fois mieux que la petite mesurette en plastique. Après lecture de quelques articles en ligne, j'ai tassé mais pas trop mon café et fait attention à ce que le café atteigne bien le filtre métallique mais n’empêche pas la fermeture.
Dans ma machine, une Citiz, aucun problème pour l'introduction. La capsule passe facilement, la fermeture du levier est aisé et la capsule n'est ni marquée ni abimée après utilisation.
Malheureusement le café est trop "flotté" à mon goût. La couleur, la mousse, tout va bien pendant une demie-tasse à expresso. Puis ça devient rapidement de la flotte quasi-transparente. Une fois la mousse un peu remontée, on se rend vite compte que le breuvage résultant est assez translucide et que le goût ressemble plus à un café filtre mousseux qu'à un expresso. Même si j'arrête la percolation rapidement, on est loin du résultat d'une capsule Nespresso d'origine...
Je vais continuer mes essais avec différentes moutures, des tassages plus ou moins forts, mais pour l'instant ce n'est pas à la hauteur de mes attentes même si le matériel reçu ne fait vraiment pas cheap. Voilà, en hopant que ça helpe.
Mise à jour : je me suis également demandé ce que le tamper donnerait avec les capsules en plastique de maïs avec obturation autocollante... Et bien c'est meilleur ! Ce n'est pas parfait mais c'est mieux que la capsule metallique...
Saturday 29 June 2019
By glazou on Saturday 29 June 2019, 08:38 - Privowny
Back in 2012, Dan Wheeler and Dropbox released the excellent zxcvbn, a password strength estimator inspired by password crackers, under an Open Source license. Pretty well done, fast and easily added to Web sites and Web apps, we at Privowny started being very interested by zxcvbn despite of a few issues:
-1 indicating a leaked password.Tuesday 28 May 2019
By glazou on Tuesday 28 May 2019, 10:21 - Franchouillardises
Les Républicains se sont donc pris une rouste maousse-costaud. Deux ans après la présidentielle, ce parti a un pied assez net dans la tombe. Malgré les commentaires larmoyants de certains (cherchez sur twitter mais soyez prévenus, c'est de la lecture difficile au petit matin, genre des anti-IVG, des cathos bien fondus, etc.), la campagne de Bellamy n'a non seulement pas été bonne, elle a été mauvaise. Je m'explique...
Avant de parler du bonhomme, il faut parler de stratégie, de ligne de campagne et d'électorat cible. Le positionnement de la campagne européenne a été très clairement le cul entre deux chaises, entre FIllon et Wauquiez. Or le premier n'a pas réussi à rassembler même son propre parti alors qu'il lui aurait fallu aller au-delà pour percer, tandis que le second est un repoussoir absolu pour les historiques RPR/UMP qui l'accusent de buissonisme effréné (à juste titre, d'ailleurs...). Une telle campagne, entre valeurs bourgeoises et cathos-tradi d'une part, frôlant de bien trop près des thèmes nets de l'extrême-droite d'autre part, ne pouvait pas faire mouche en 2019. Il est d'ailleurs passionnant de noter que seuls 34% des électeurs de Fillon en 2017 ont voté Bellamy en 2019, excusez du peu. Ce n'est plus une rouste, c'est un coup de poing dans le ventre.
Si vous avez bien suivi comme moi la "campagne" des européennes, que nous a proposé LR dans le poste et sur les radios récemment ?
Thursday 21 February 2019
By glazou on Thursday 21 February 2019, 22:57 - Franchouillardises
Je viens de passer plusieurs heures avec mon fils à brouter du ParcoursSup. Après avoir passé des bons moments à chercher pour lui la formation idoine. J'avais pensé, j'avais cru ne pas avoir engendré deux babasseurs pour fils mais eh, j'ai été rattrapé par la réalité... Le premier écrivait son premier jeu pour Android à 15 ans et le second se passionne pour l'intelligence artificielle et le Machine Learning.
Si l'aîné a plongé dans une MathsSup comme sortie normale de Terminale S (alors qu'il aurait très bien pu présenter SciencesPo), le cadet est moins intéressé par le rythme somme toute totalement délirant des CPGE. Je ne peux pas lui donner tort... On a donc cherché autre chose.
Eh bien le résultat est relativement clair :
Quant à ParcoursSup, mon fils a du répondre à un auto-QCM pour les candidatures Fac/IUT. Il a choisi, ô surprise, Maths/Informatique. Les questions étaient consternantes de nullité, voire de bêtise crasse. Quand je dis auto-QCM, cela signifie donc que le gamin est seul devant son navigateur Web et que l'onglet 1 est ouvert sur le questionnaire ; il va sans dire que le slacker (mais pas mon fils) aura l'onglet 2 ouvert sur Wikipedia ou tout autre ressource immédiatement utile. Non mais quel est le bachi-bouzouk qui a inventé ce machin ? Pour certaines questions, c'était même pire : une vidéo de quatre minutes (si, si) était à voir/écouter et les réponses à trois questions étaient DIRECTEMENT fournies dans la video... Tout cela fait, le moutard doit fournir n, avec n grand selon la formule consacrée, lettres de motivation voire CVs ! Mais bordel de Zeus, on parle d'un gamin de 17 ans qui sort des jupes de sa mère, n'a rien encore vécu professionnellement puisque justement il espère beaucoup de sa formation post-Bac. Et avec ça on va inonder tous les établissements de France et de Navarre avec près de 700 000 lettres de motivation fois 10 candidatures par moutard, soit près de 7 MILLIONS DE LETTRES DE MOTIVATION. Alors arrêtons d'être faux-culs, la vaste majorité d'entre elles n'est pas lue, le nombre d'hommes-années pour les lire toutes est hallucinant ; elles finissent donc poubellisées sans autre forme de procès et on devrait arrêter les frais pour la prochaine session ParcoursSup avant qu'on n'atteigne la fourniture d'une analyse de matière fécale pour compléter son dossier.
En conclusion, je dirais que la France a besoin d'une vingtaine d'Epita. Elle a également besoin, toujours besoin, d'un grand coup pied dans le cul en ce qui concerne l'Informatique mais là, malheureusement, rien de nouveau sous le soleil. Quant à ParcoursSup, c'est un pansement sur une jambe de bois. Le système éducatif supérieur français a fini d'être mis en place alors que moins de 70% d'une classe d'âge obtenait son Bac. Or en 2018, le Bac général a un taux de réussite de 91.1%, excusez du peu. Notre système est saturé, il n'en peut plus, il craque de toute part. Nous payons des décennies de sous-investissement dans ce qui est l'avenir du pays, son éducation. Il faut arrêter de prendre les gens pour des veaux : ParcourSup, c'est la sélection qu'on n'a pas le droit, pour l'instant, d'appliquer. Ouvrons les yeux, le nouveau prolétariat est prêt, il a le Bac - et rien que le Bac...
PS: il a fallu des décennies pour que l'INRIA quitte récemment les préfabriqués indigents de Rocquencourt. Je me rappellerai longtemps de ce chercheur américain, rencontré à Stanford, me racontant son effarement à son arrivée à Rocquencourt dans un préfab entre la caserne de pompiers et la voie rapide.. Voilà, tout est dit.
Wednesday 23 January 2019
By glazou on Wednesday 23 January 2019, 11:47 - Standards
The Open Web Platform is a careful and fragile construction billions of people, including millions of implementors rely on. HTML, CSS, JavaScript, the Document Object Model, the Web API and more are all standardized one way or another; that means vendors and stakeholders gather around a table to discuss all changes and that these changes must pass quality and/or availability criteria to be considered "shippable".
One notable absent from the list of Web Standards is WebExtensions. WebExtensions are the generalized name of Google Chrome Extensions that became mainstream when Google achieved dominance over the desktop browser market and when Mozilla abandoned its own, and much more powerful, addons system based on XUL and privileged scripts.
As a reminder, the WebExtension API allows coders to implement extensions to the browser based on:
chrome-extension://
URLA while ago, at a time Microsoft still had its own rendering engine, it initiated a Community Group on WebExtensions at the World Wide Web Consortium (W3C). With members from most browser vendors plus a few others, this seemed to be a very positive move not only for implementors but also for users.
But unfortunately, that effort went nowhere. Lack of commitment from other browser vendors and in particular Google, Microsoft abandoning its own rendering engine, lax Community Group instead of a formal W3C Working Group, the WebExtension draft specification has been in limbos for a while now and WebExtensions clearly remain the poor parent of Web Standards even if most people have at least one browser extension installed (usually some sort of ad-blocker).
Today, Google is impulsing a deep change in its WebExtension model:
webRequest API that billions of users activate on a
daily basis to block advertisement, trackers or undesirable content, is
at stake and should be replaced by a declarartive new API that will not
allow to monitor the requested resources any more. At a time the
advertisement model on the Web is harmed by ad blockers, one can only
wonder if this change is triggered only by technical considerations or
if ad strategy is also behind it... Furthermore, it will be limited to a few dozens of thousands of declarations, which is far below the number of trackers
and advertisement scripts available in the wild today.On the webRequest part specifically, all major actors of
the ad-blocking and security landscape are screaming (see also the chromium-extensions Google group). Us at Privowny are
also deeply concerned by the v3 proposed changes. Even Amnesty
International complained in a recent message! To me, the most important message posted in reply to the proposed changes is the following one:
Hi, we are the developer of a child-protection add-on, which strives to make the Internet safer for minors. This change would cripple our efforts on Chrome.
Talk about "don't be evil"...
All of that gives a set of very bad signals to third-party implementors, including us at Privowny:
Reading the above, and given the fact Google is able to impulse changes of such magnitudes with little or no impact study on vendors like us, we consider that WebExtensions are not a safe development platform any more. We will probably study soon an extraction of most of our code into a native desktop application, leaving only the minimum minimorum in the browser extension to communicate with web pages and of course with our native app.
After Mozilla that severely harmed its amazing addons ecosystem (remember it triggered the success of Firefox), after Apple that partly went away from JavaScript-based Safari extensions jeopardizing its addons ecosystem so much it's anemic (I could even say dying), Google is taking a move that is harmful to Chrome extensions vendors. What is striking here is that Google is making the very same mistake Mozilla did: no prior discussion with stakeholders (hear extension implementors), release of a draft spec that was obviously going to trigger strong reactions, unmeasured impact (complexity, time and finances) on implementors, more and more restrictions on what it is possible to do but a too limited set of new features.
On the legal side of things, this unilateral change could probably even qualify as "Abuse of dominant position" under European Union's article 102 TFUE, and could then cost Google a lot, really a lot...
The Open Web Platform is alive and vibrant. The Browser Extension ecosystem is in jail, subject to unpredictable harmful changes decided by one single actor. This must change, it's not viable any more.
Monday 7 January 2019
By glazou on Monday 7 January 2019, 19:15 - Franchouillardises
Madame la Ministre, chère cousine (je suis le fils de Sarah Burzyn ; mon père Maurice et moi-même saluons chaleureusement Elie. Maurice qui est toujours également avec nous se ferait une joie de le revoir),
Je souhaite vous alerter aujourd'hui sur un changement récent impactant gravement les personnes souffrant de rhumatismes douloureux, souvent inclassés. Un produit dédié par AMM aux douleurs du zona, le Versatis 700mg, est un emplâtre médicamenteux à la Lidocaïne. Il est souvent et facilement utilisé, sous prescription, dans le cas de douleurs tendineuses ou articulaires persistantes et donne des résultats très positifs : s'il ne guérit rien, il permet par exemple d'atténuer des douleurs au point de pouvoir trouver le sommeil et présente peu de danger. Son utilité en rhumatologie est avérée, et facile à démontrer.
Or, je le redis, ce produit est dédié par AMM au zona. Devant la recrudescence des usages rhumato de ce produit, il a été déremboursé pour tout autre usage au 1er janvier 2019. Or chaque boîte de 30 emplâtres coûte la bagatelle de 70€ environ... Même sur prescription d'un rhumatologue, même sur prescription formelle du Centre de Rhumatologie du CHU Henri-Mondor, il faut désormais payer plein pôt le Versatis. Ce déremboursement laisse donc tous les usagers "rhumato" du Versatis devant un choix impossible : des douleurs permanentes et/ou invalidantes, ou un budget conséquent de dépenses imprévues.
J'utilise personnellement ce produit dans le cadre d'une aponévrosite plantaire très douloureuse, et ma compagne dans le cadre d'un rhumatisme inclassé très douloureux.
J'ai donc l'honneur de vous demander l'annulation en urgence de ce déremboursement. À une époque où la prise en compte de la douleur est enfin réalisée, ce déremboursement est un signal incompréhensible et laisse les patients sans option de rechange. Si je peux me permettre cette dépense, l'idée que d'autres ne le puissent et que ce déremboursement induise un inégalité devant la douleur m'est insupportable.
Respectueusement,
Daniel Glazman
Sunday 9 December 2018
By glazou on Sunday 9 December 2018, 11:09 - Microsoftisms
I am quite surprised by all the public reactions I read about Microsoft's last browser moving to Chromium. I think most if not all commenters have missed the real point, a real point that seems to me way bigger than Edge. Even Mozilla's CEO Chris Beard has not mentioned it. People at Microsoft must be smiling and letting go loud french « Ahlala...». Let me remind everyone that a browser is, from a corporate point of view, a center of cost and not a center of revenue; if you're really nitpicking, you can call it a center of indirect revenue. So let's review and analyse the facts:
So I think the whole thing is not about Edge. The microcosm reacted, and reacted precisely as expected (again, probable laughters in Redmond), but this is really about Windows and the core of activity of Microsoft. Impulsing a change like a move to Chromium and using it as a public announcement by a Windows CVP, is, beyond technical and business choices, a political signal. It says « expect the unexpected ».
I think Microsoft Windows as we know it is about to change and change drastically. Windows as we know it could even die and Microsoft move to another new, different operating system, Edge+Chromium's announcement being only the top of the iceberg. And it's well known that 9/10th of an iceberg remain below water surface.
The gravity center of the company is then about to change too; Nadella probably knows too well the impact of the Windows division on the rest of the company during the Vista years and he certainly knows too well the inter-division wars at Microsoft. It could be highly time to shake the whole thing. As I told Dean Hachamovitch long ago, « you need a commando and what you have now is a mexican army with a lot of generals and not enough soldiers ». Still valid?
Of course, I could be partially or even totally wrong. But I don't think so. This announcement is weird on too many counts, and it's most certainly on purpose. It seems to be telling us « guys, read between the lines, the big message is right there ».
Monday 27 August 2018
By glazou on Monday 27 August 2018, 17:43 - Mac
Vous regrettez amèrement l'option « N'importe où » vous autorisant à installer/lancer sur votre OS X des applications sans contrôle de leur origine ?

Une simple ligne de commande peut vous aider :
sudo spctl --master-disable
Après avoir quitté et relancé les préférences, votre option préférée sera de nouveau là :
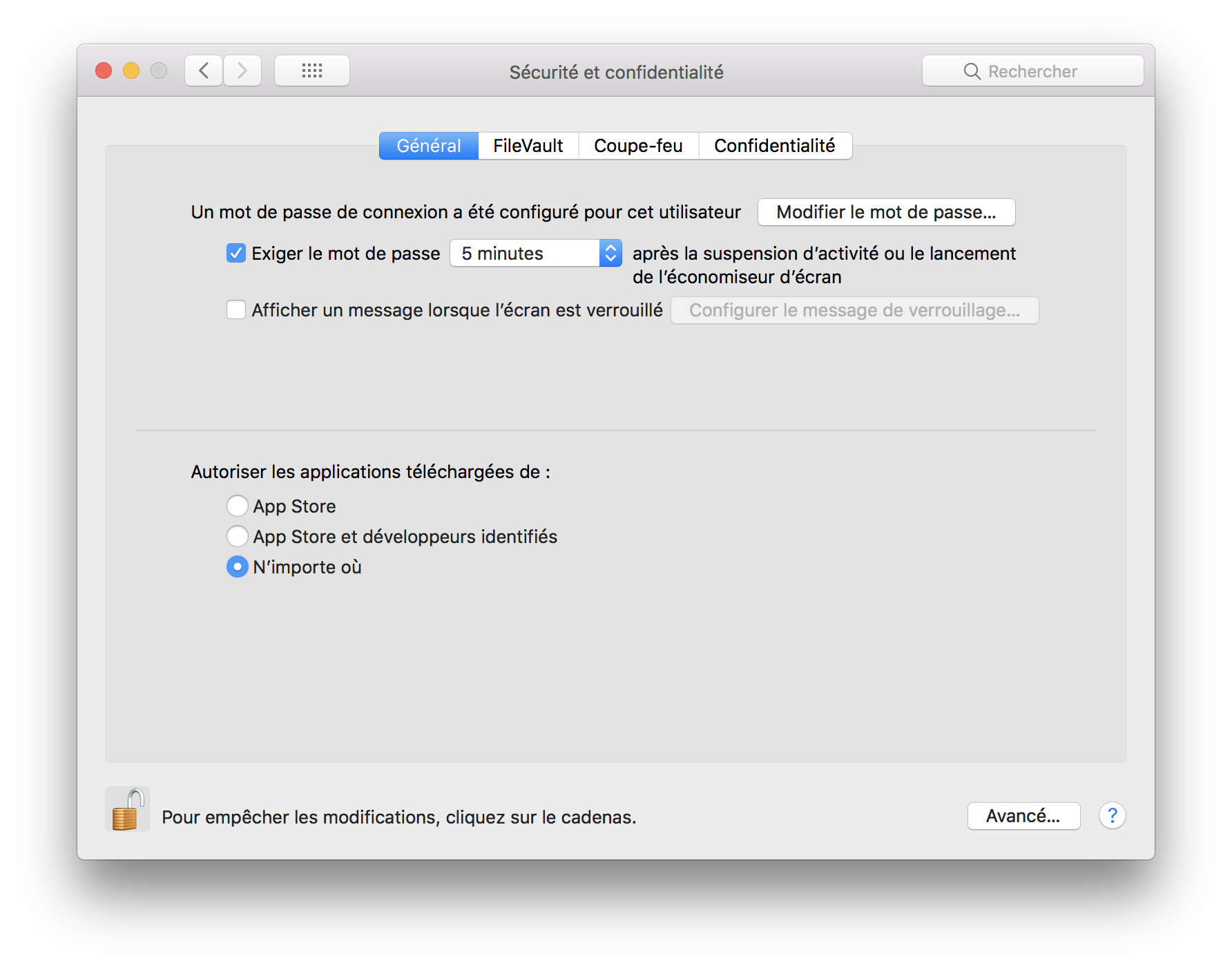
Pour revenir à l'état antérieur, une autre ligne de commande :
sudo spctl --master-enable
Thursday 7 June 2018
By glazou on Thursday 7 June 2018, 15:14 - Standards
Just for the record, if you really need to know about the browser container of your WebExtension, do NOT rely on StackOverflow answers... Most of them are based, directly or not, on the User Agent string. So spoofable, so unreliable. Some will recommend to rely on a given API, implemented by Firefox and not Edge, or Chrome and not the others. In general valid for a limited time only... You can't even rely on chrome, browser or msBrowser since there are polyfills for that to make WebExtensions cross-browser.
So the best and cleanest way is probably to rely on chrome.extension.getURL("/") . It can start with "moz", "chrome" or "ms-browser". Unlikely to change in the near future. Simple to code, works in both content and background.
My pleasure :-)
« previous entries - page 1 of 289
